AbstractLess

"It’s easier to add complexity to a simple system than to simplify a complex one."
What is Abstraction?
In programming, abstraction is a technique of arranging code complexity by defining separate levels of system functionality. Abstractions are specific parts of code responsible for different things. Ideally, abstractions make the code easier to extend, read, understand, and maintain.
What is AbstractLess?
AbstractLess is a mindset aimed at avoiding overengineering in software development. The approach is simple: build only what you truly need. This reduces unnecessary layers, keeps your code clean, and ensures flexibility for future changes.
Abstractless inspired following approaches:
- KISS (Keep It Simple, Stupid): Begin with a clean, direct approach. Resist adding extra frameworks or layering “just in case.”
- YAGNI (You Ain’t Gonna Need It) - Don’t implement functionality or architectural elements ahead of demonstrated needs. Base decisions on actual data (performance bottlenecks, domain complexity, team constraints), not guesses about the future.
In software development, we often see many popular patterns and ideas: microservices, Clean Architecture, event-driven systems, and more. These can be helpful in some cases, but using them too early can create unnecessary complexity.
Understanding System Complexity
In software projects, we can differ between simple, complicated, and complex systems based on how well we understand the problem and solution:
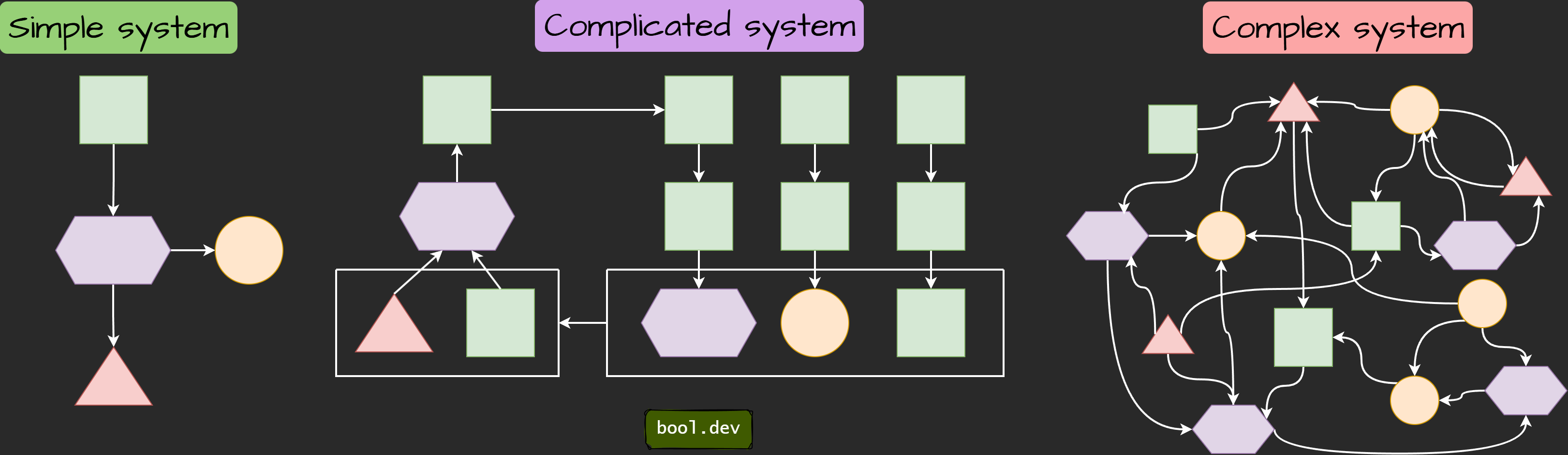
Complicated: Requires expert knowledge, but parts are predictable (e.g., enterprise applications with microservices).
Complex: Interactions are unpredictable due to many interlinked parts (e.g., real-time trading systems).
Common Pitfalls
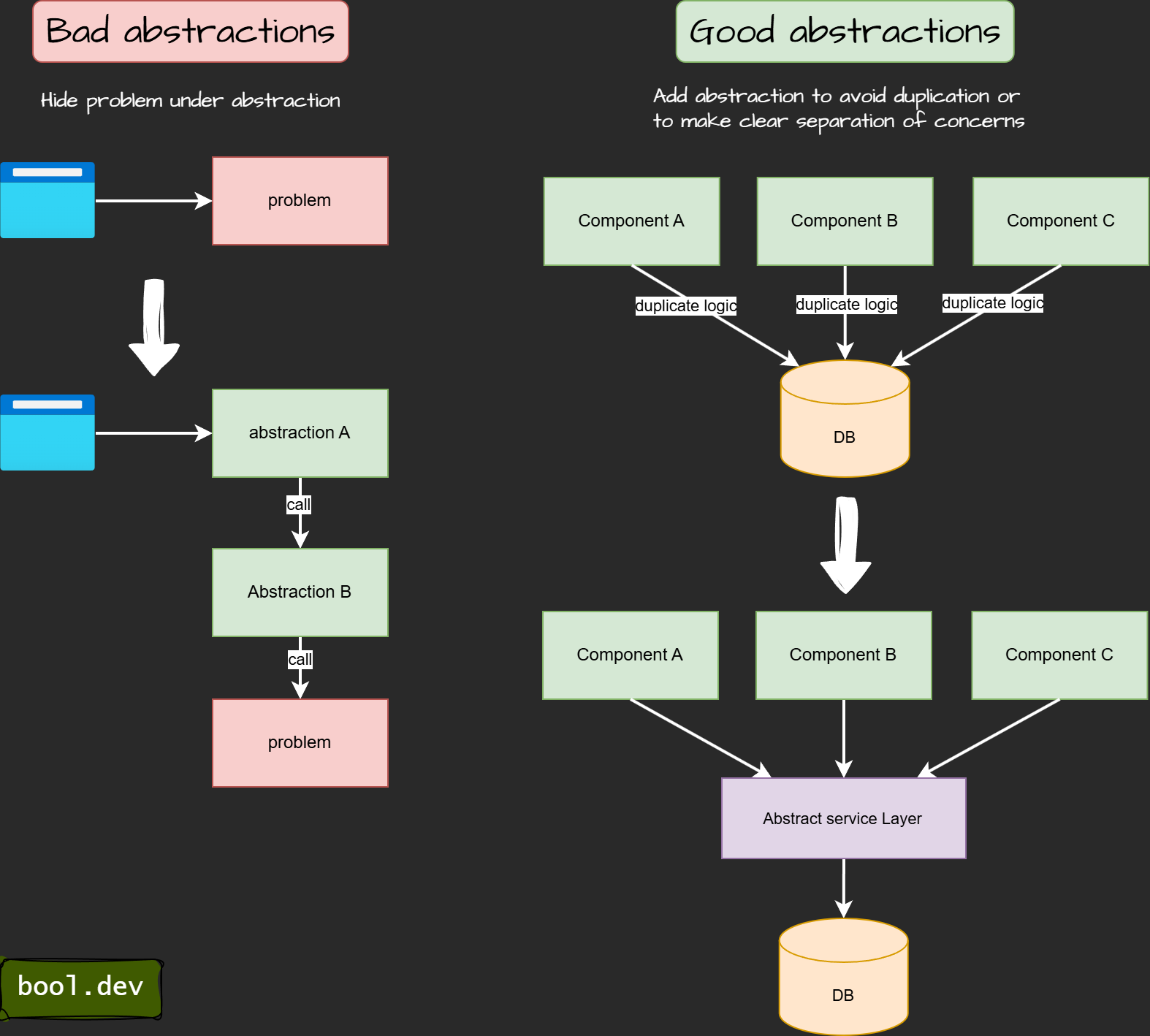
Even with the AbstractLess mindset, there are pitfalls to watch out for:
- Over-Simplification. When considering minimalism, avoid removing necessary structure, layers, and patterns. Some complexity is required for maintainability.
- Ignoring Future Growth. While the YAGNI principle is valuable, it's equally important to consider potential scaling needs. This forward-thinking approach can prevent significant refactoring and prepare your system for future demands.
- Not all abstractions are bad—some provide value by improving code organization and reducing duplication.
- A strict approach to simplicity can prevent the adoption of necessary improvements or new technologies.
Applying AbstractLess at the system architecture level
Inspired by DDD, many architects jump into microservices without considering the monolith first approach by default, which very closely aligns with AbstractLess, starting simple and scaling where needed.
When to migrate into microservices
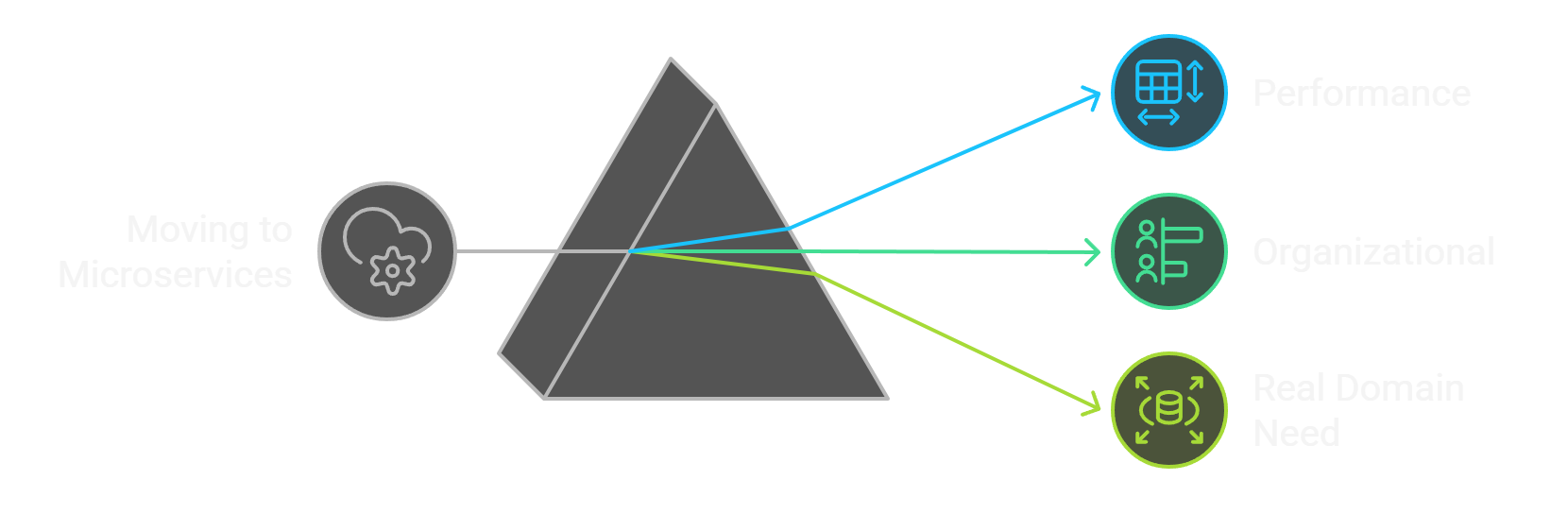
- One part faces unique scaling needs.
- Different teams require independent release cycles.
- Clearly defined bounded contexts exist.
Ensure microservices address real problems, not just introduce new ones like deployment complexity or latency issues.
Applying AbstractLess to the project structure level
When discussing components, a usual approach that many people might have in mind is CleanArchitecture.
Consider what you really need. The CleanArchitecture template is just one of the options, not a silver bullet for all your needs.
Clean architecture typically has the following structure:
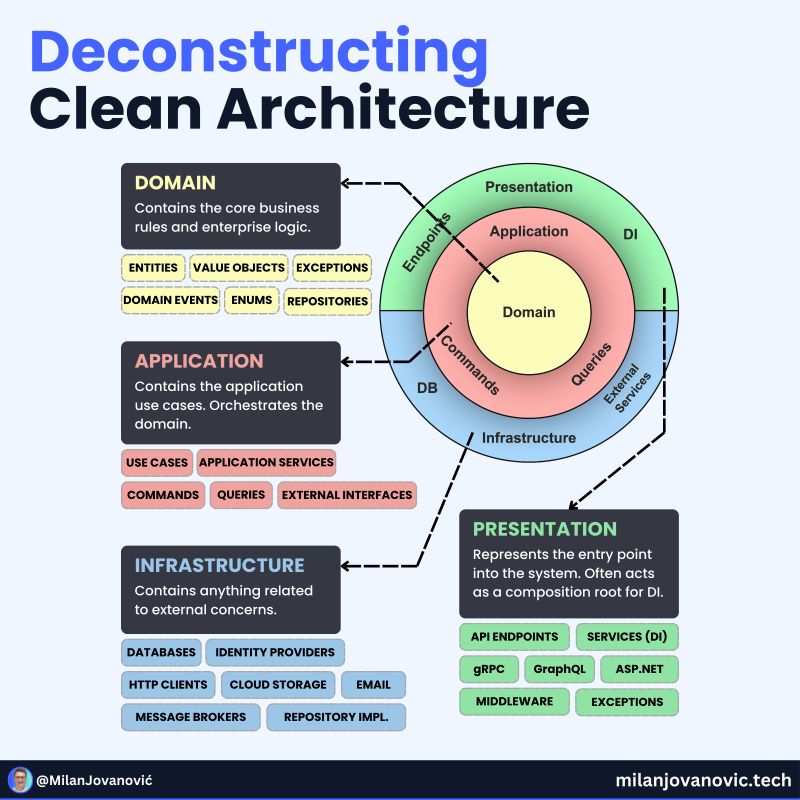
Clean architecture has advantages but might also be an overhead for some solutions. For example, Clean Architecture might be a good fit if you use monolith, SoA, or plug-in architecture (read more about architecture styles in our article). However, I have seen a few times that the Clean Architecture approach is used when a team works with microservices and usually causes unnecessary complexity. Why? It might not be a good idea because splitting the application by nature should be small. Also, if you follow the monolith first approach, Clean Architecture might not be the best choice. For example, Vertical Slice Architecture might be a good choice as it's an easily copied and pasted folder with everything related to the domain in the new service.
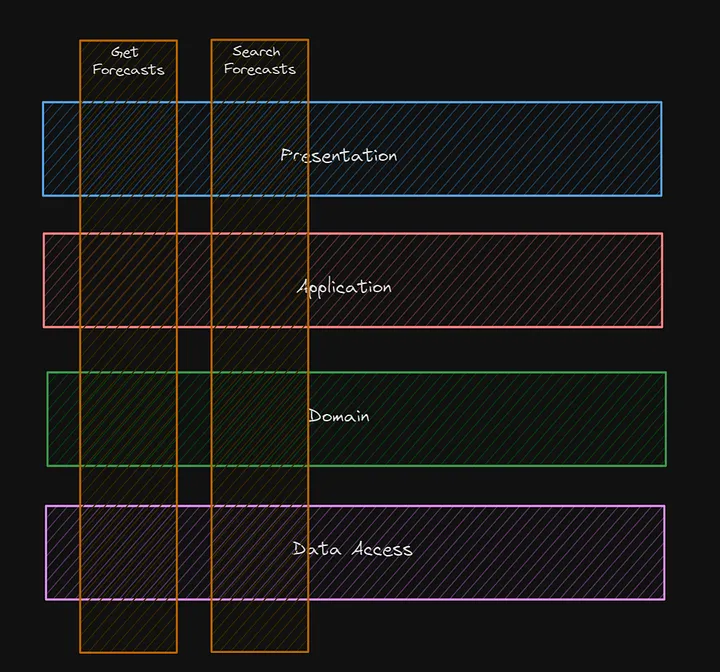
Microsoft also provided a reasonable breakdown and created an article on simplifying the CleanArchitecture approach.
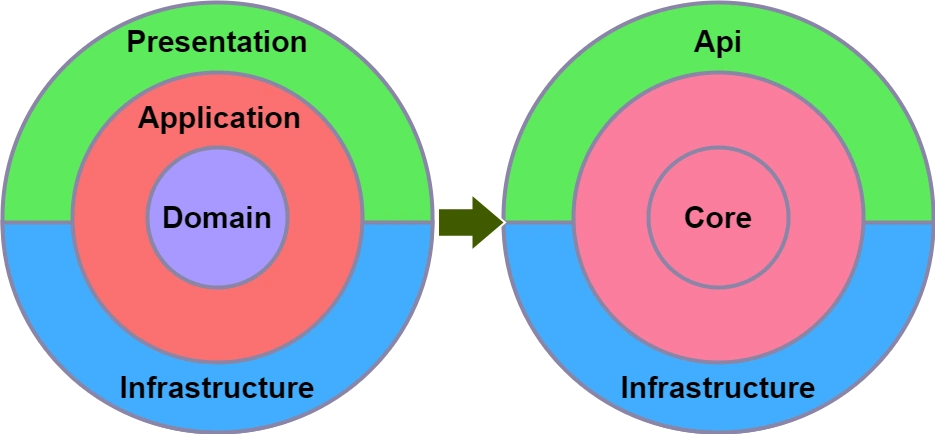
Applying AbstractLess at the code level
Avoid unnecessary abstractions that add overhead without real benefits. Do not hide the problem behind layers of abstractions; use abstractions to solve them.
Note: It makes sense if you add some additional logic on top of it, but if you replicate logic, it's not the best approach.
For example, a violation of the abstractless approach will be adding abstraction on top of libraries:
❌ Don't do:
public interface IMyLogger
{
void Log(string message);
}
public class MySerilogAdapter : IMyLogger
{
private readonly ILogger _logger;
public MySerilogAdapter(ILogger logger)
{
_logger = logger;
}
public void Log(string message)
{
_logger.Information(message);
}
}✔️ Do
private readonly ILogger _logger;
public void LogMessage(string message)
{
_logger.Information(message);
}Let's consider the example refers to EF Core DB context:
What the first idea do you have in mind if I ask you to create a method in the controller to insert books into Books table
Right! You will answer that ServiceClass and the Repository class should be added, like:
public interface IBooksRepository
{
Task AddAsync(Book book);
}
public class BooksService
{
private readonly IBooksRepository _booksRepository;
private readonly DbContext _context;
public BooksService(IBooksRepository booksRepository)
{
_booksRepository = booksRepository;
}
public async Task AddBookAsync(Book book)
{
await _booksRepository.AddAsync(book);
await _booksRepository.SaveChangesAsync();
}
}It looks pretty standard to what we do every day, right?
Let's consider more complex things.
For example, we should introduce a warehouse, change available books inside the concrete warehouse, and make it in the same transaction. Then we should implement WarehouseRepository, and we have to implement a Unit Of Work, as it's required to have a saving process under the same transaction:
public interface IUnitOfWork : IDisposable
{
IBooksRepository BooksRepository { get; }
IWarehouseRepository WarehouseRepository { get; }
Task<int> SaveChangesAsync();
}
public interface IBooksRepository
{
Task AddAsync(Book book);
}
public interface IWarehouseRepository
{
Task<Warehouse> GetByIdAsync(int id);
Task UpdateAsync(Warehouse warehouse);
}
public class UnitOfWork : IUnitOfWork
{
private readonly DbContext _context;
public IBooksRepository BooksRepository { get; }
public IWarehouseRepository WarehouseRepository { get; }
public UnitOfWork(DbContext context, IBooksRepository booksRepository, IWarehouseRepository warehouseRepository)
{
_context = context;
BooksRepository = booksRepository;
WarehouseRepository = warehouseRepository;
}
public async Task<int> SaveChangesAsync()
{
return await _context.SaveChangesAsync();
}
public void Dispose()
{
_context.Dispose();
}
}
public class BooksService
{
private readonly IUnitOfWork _unitOfWork;
public BooksService(IUnitOfWork unitOfWork)
{
_unitOfWork = unitOfWork;
}
public async Task AddBookAsync(Book book)
{
await _unitOfWork.BooksRepository.AddAsync(book);
var warehouse = await _unitOfWork.WarehouseRepository.GetByIdAsync(book.WarehouseId);
if (warehouse != null)
{
warehouse.AvailableBooks++;
await _unitOfWork.WarehouseRepository.UpdateAsync(warehouse);
}
await _unitOfWork.SaveChangesAsync();
}
}Seems pretty standard, and you saw a lot of projects following that approach, right? What's wrong here?
If you check the source code of DBcontext, you will find that:
A DbContext instance represents a session with the database and can be used to query and save
instances of your entities. DbContext is a combination of the Unit Of Work and Repository patterns.
Insane! That means that to follow business logic, we will implement Repository and UoW on top of the Repository and UoW that the Microsoft team implements.
Should we avoid using Repository and Unit of Work at all?
My answer - nope! Your business logic still might require creating repositories for some domain logic:
- You have special domain rules that apply to each data call (for example, global filters).
- You use different data sources (like a mix of SQL and NoSQL) and need one interface to handle them all.
- You need specific raw SQL or complicated queries and want to isolate them from the rest of your logic.
If you don’t have these needs, you can use the DbContext directly. That is the AbstractLess way.
Main Takeaways
Make systems abstractless by default:
- Keep Abstractless in mind
- Start Simple
- Build Only What You Need
- Keep software flexible and pragmatic-scalability; other layers should follow real-world requirements, not hypothetical ones.
Future reading
- MonolithFirst
- Vertical Slice Architecture
- The Frugal Architecture: Cloud Cost Efficiency in Practice
- GRASP Principles
- SOLID Principles Cheat Sheet
- Top 10 Software Architecture Styles You Should Know
- Scale Cube: A Guide to Scalability in System Architecture
- Reference Architecture Cheat Sheet
- Best Practices for Effective Software Architecture Documentation
- 6 Steps to scale your application in the cloud