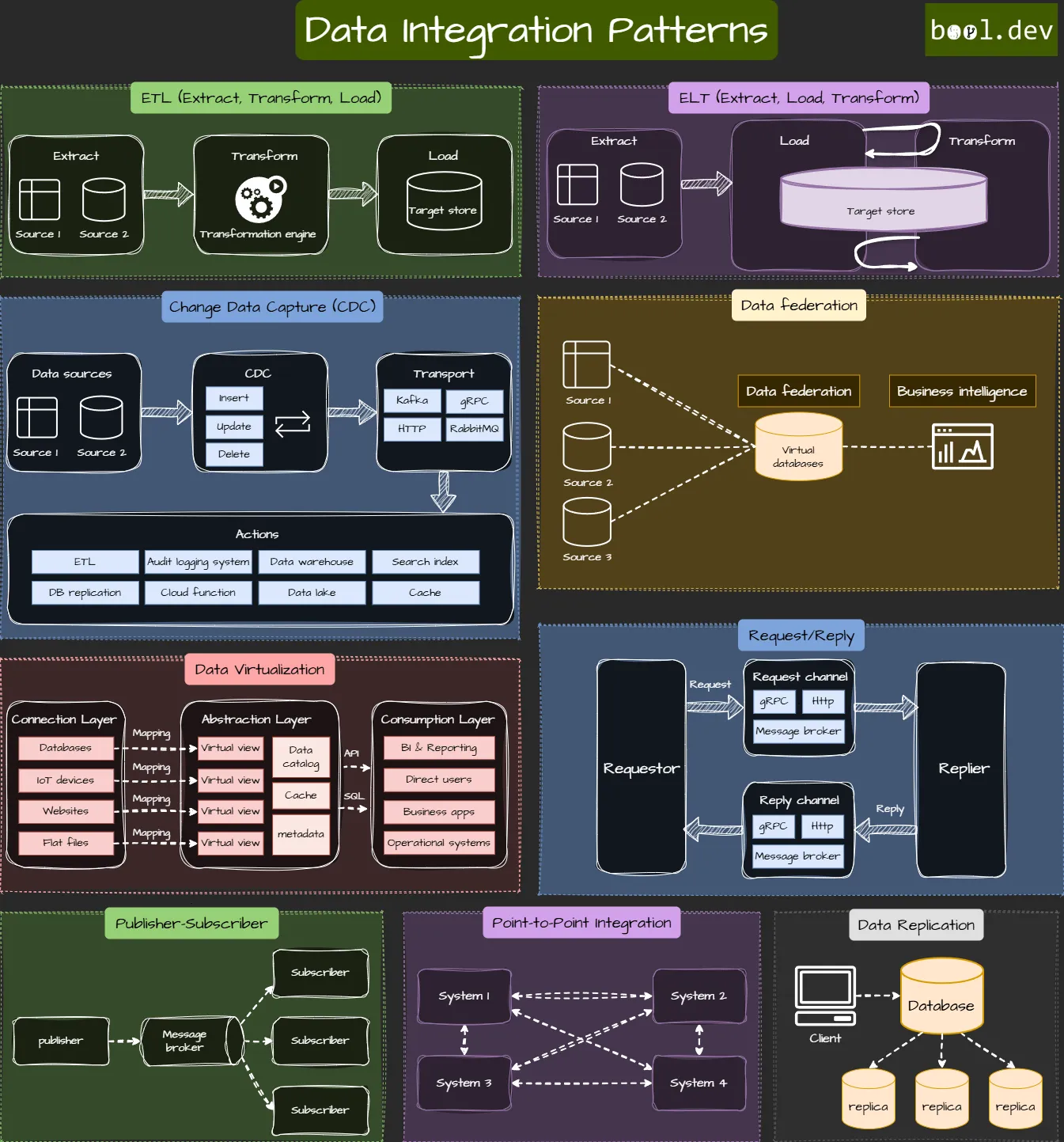
Data Integration Patterns
Data integration patterns can assist when business processes require integrating data from various sources, including multiple databases, social networks, IoT devices, flat files, and more.
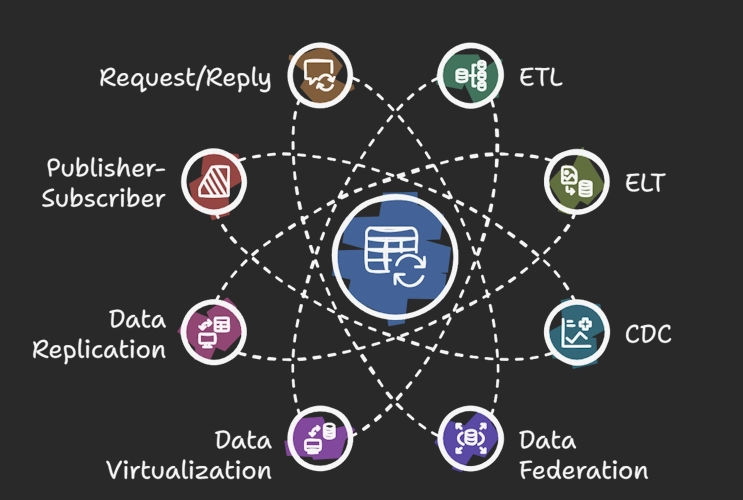
This article explores essential data integration patterns, including ETL, ELT, Change Data Capture (CDC), Data Federation, Data Virtualization, Data Replication, Publish/Subscribe, Request/Reply, and Point-to-Point Integration. Learn how and when to use these patterns for efficient data handling and real-time analytics. Also, the article contains 'real world' examples that give you more understanding of each data integration type.
ETL (Extract, Transform, Load)

ETL stands for Extract, Transform, and Load. It is common to gather data from various sources, process it to meet specific requirements and load it into a target system, such as a data warehouse. ETL is beneficial in environments where data must be extensively cleaned and transformed to ensure quality and consistency before analysis, such as in traditional enterprise systems or when dealing with legacy data sources.
When to Use ETL
- When you need organized, cleaned-up data for reports.
- Suitable for environments where cloud-based tools, such as Azure Data Factory or Google BigQuery, are available for processing.
ETL can sometimes be slow and complex, requiring significant computational resources and storage. This makes it less useful for real-time needs or when systems must efficiently handle large, dynamic datasets.
🧑🍳 Real World Kitchen Analogy for ETL
ELT (Extract, Load, Transform)

ELT is similar to ETL, but you load the data before transforming it. You first extract the data and load it into a target system, often a data lake. Then, you transform it using the tools available in that system. ELT is usually used with big data systems that can handle heavy processing.
When to Use ELT
- When you have a lot of raw data in a data lake.
- When you can use cloud tools to process the data.
🧑🍳 Real World Kitchen Analogy for ELT
CDC (Change Data Capture)
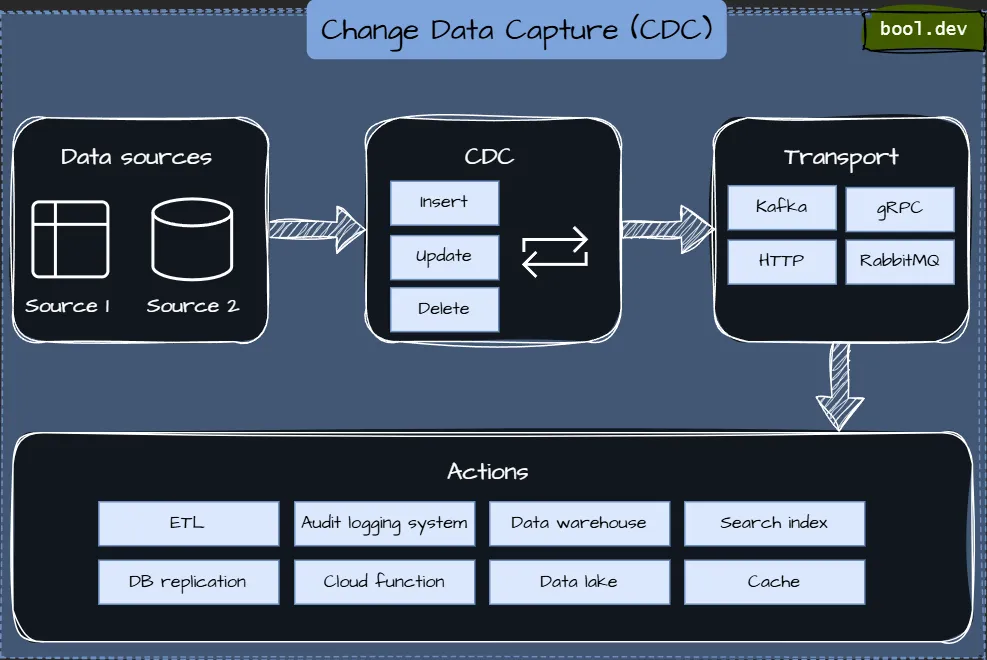
Change Data Capture is a method used to track and record changes made to a database table, allowing for real-time data updates to other systems.
On a high level, the CDC tracks changes in a source dataset, such as a transactional database. It automatically transfers those changes to a target dataset, like a data warehouse or analytics platform.
When to use CDC
- When you need real-time updates.
- It is useful for streaming data or for systems that need quick updates.
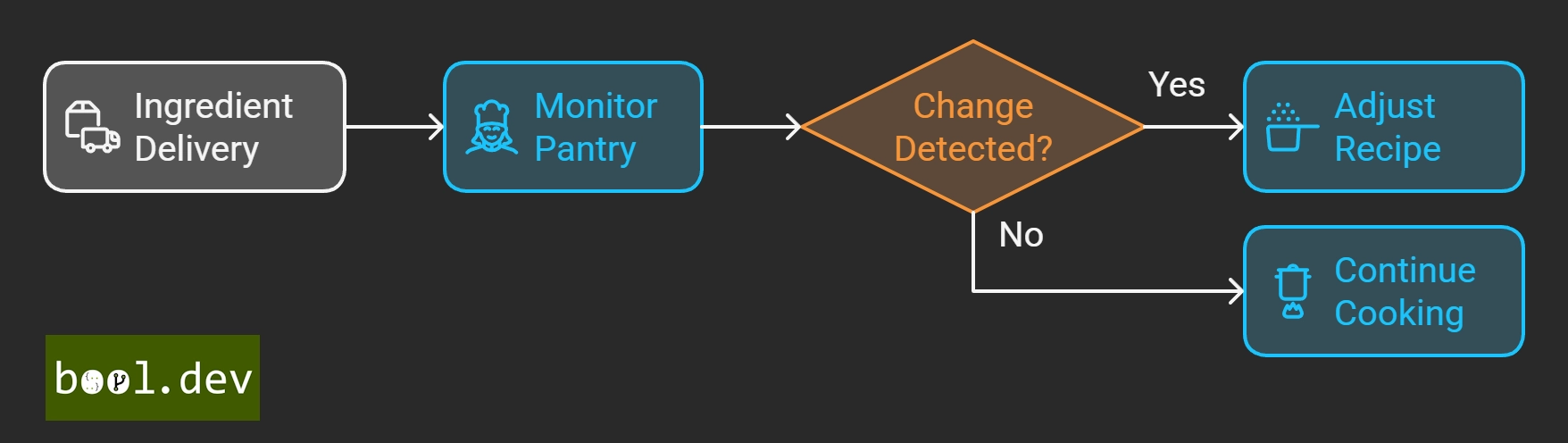
🧑🍳 Real World Kitchen Analogy for CDC
Data Federation
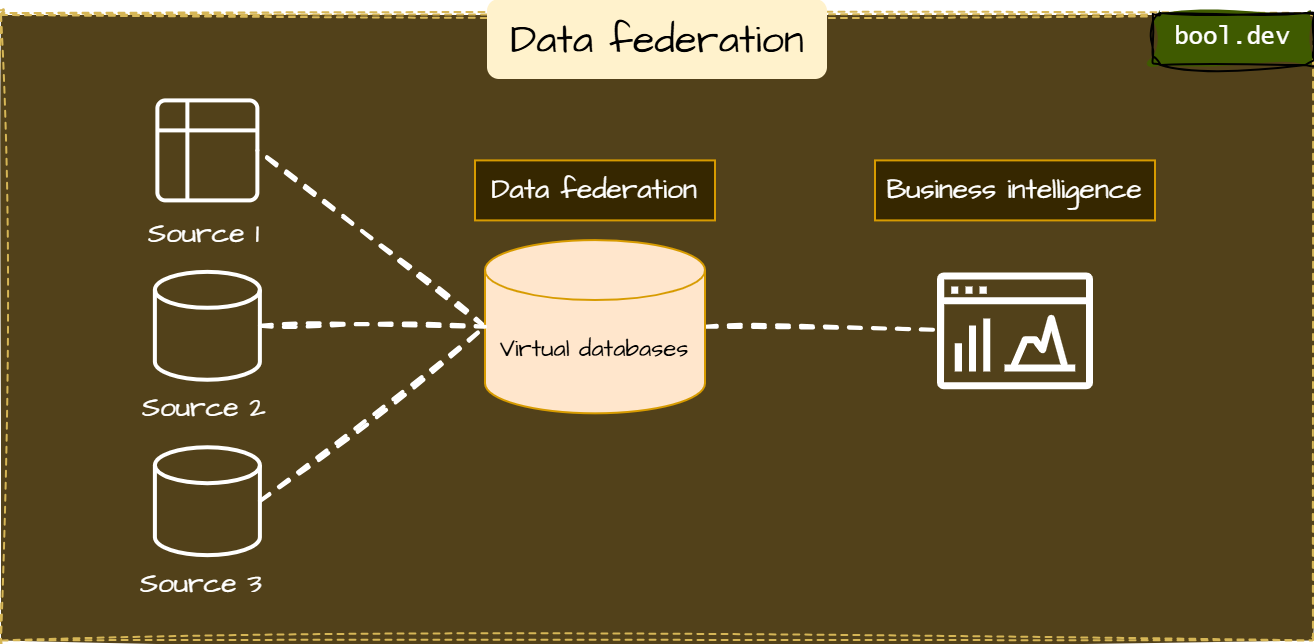
Data Federation refers to a distributed query approach that combines data from multiple sources and presents it as a single logical database. The data often remains in its source location, but queries are executed across systems, and results are combined into one output.
Data federation often involves running queries against data in multiple systems and merging the results into a unified response, often after some transformation. It generally relies on the concept of a federated database or middleware layer.
When to use data federation
- When you need a unified view of data without making extra copies.
- When data is spread across different systems.
- It is suitable for environments where data resides in different databases but needs to be queried as if from a single source, such as in reporting or analytics.
🧑🍳 Real World Kitchen Analogy for Data Federation
Data Virtualization
Data Virtualization is similar to Data Federation but focuses more on giving real-time access to data across different systems. It allows you to get data from other places without actually moving it.
It abstracts data access from the physical data sources. Instead of copying data into a centralized repository, data virtualization provides a virtual layer over the existing data systems, delivering real-time data access and query capabilities.
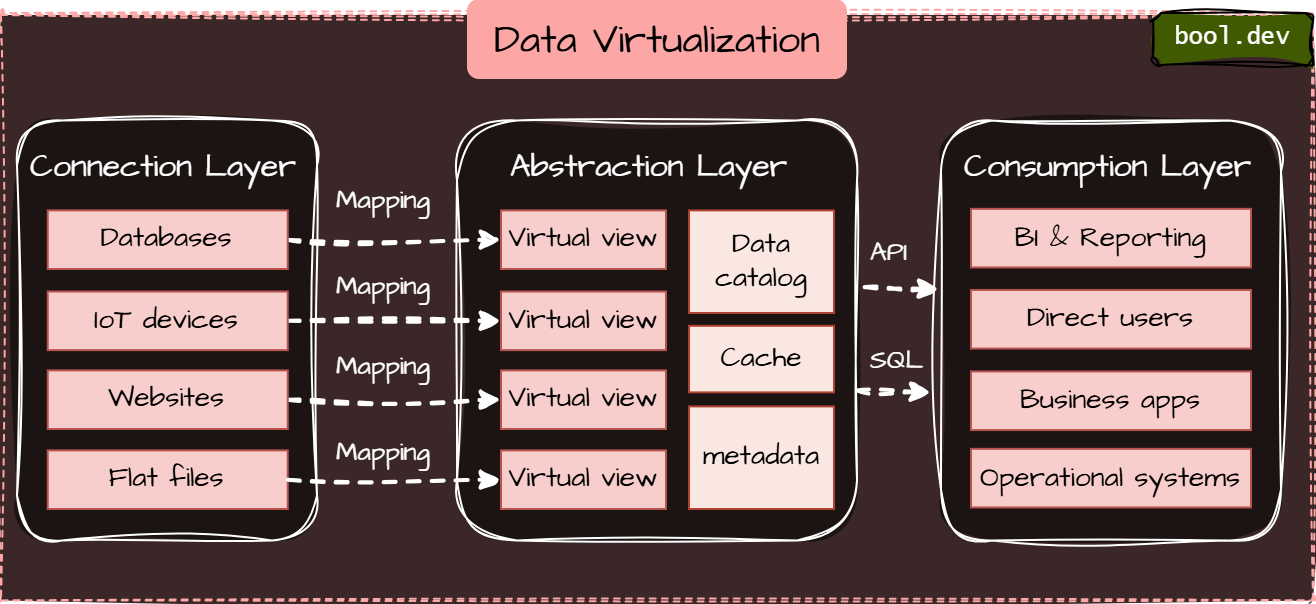
Connection Layer
- Role: Accesses a broad range of data sources, from structured to unstructured (e.g., SQL databases, big data systems, cloud repositories).
- Tasks: Uses connectors to access specific data sources, normalizes data, and converts types to make all views appear relational for higher layers.
Abstraction Layer
- Role: Links business users to data sources, forming the system's backbone.
- Tasks: Handles data transformations and logical operations, creating abstracted data views from base views. Allows metadata modeling, data transformations, and data quality management using SQL and relational tools.
Consumption Layer
- Role: Provides a unified access point for data interaction.
- Tasks: Delivers data in various formats (e.g., JSON, XML, SQL, Excel) through web services, APIs, and multiple data access protocols (SOAP, ODBC, JDBC). It meets the business user's needs for data access and presentation.
When to use data virtualization
- Ideal for organizations that need to access real-time, live data from multiple systems without the overhead of data replication.
- Useful for quick reporting or real-time analytics.
🧑🍳 Real World Kitchen Analogy for Data Virtualization
You just see them all at once without actually moving them.
Data Virtualization vs Data Federation

- Real-Time Access: Data virtualization offers real-time data access, whereas data federation can involve some latency due to the nature of querying and combining results from multiple sources.
- Data Transformation: Data virtualization often includes data transformation as part of the query process, while data federation tends to focus more on merging results without significant transformations.
- Data Movement: Data virtualization does not move or replicate data, whereas data federation might move data between systems in the process of creating a unified query result.
- Query Complexity: Data federation may struggle with complex queries compared to data virtualization, which allows for more flexibility in handling transformations and combining diverse data sources.
Data Replication
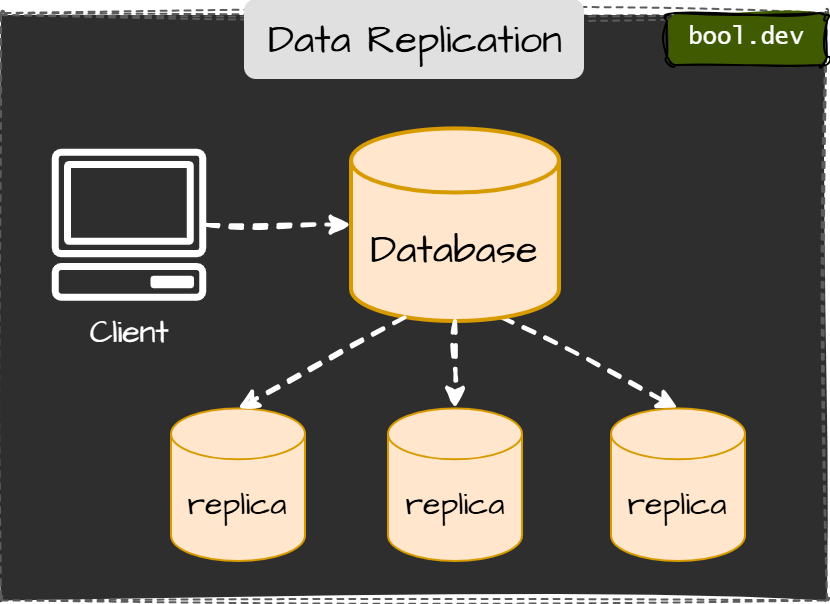
Data Replication copies data from one system to another. It is often used for backups, redundancy, and ensuring availability.
When to use data Replication
- When you need backups or high availability.
- When data should be closer to different services or regions.
🧑🍳 Real World Kitchen Analogy for Data Replication
Publisher-Subscriber
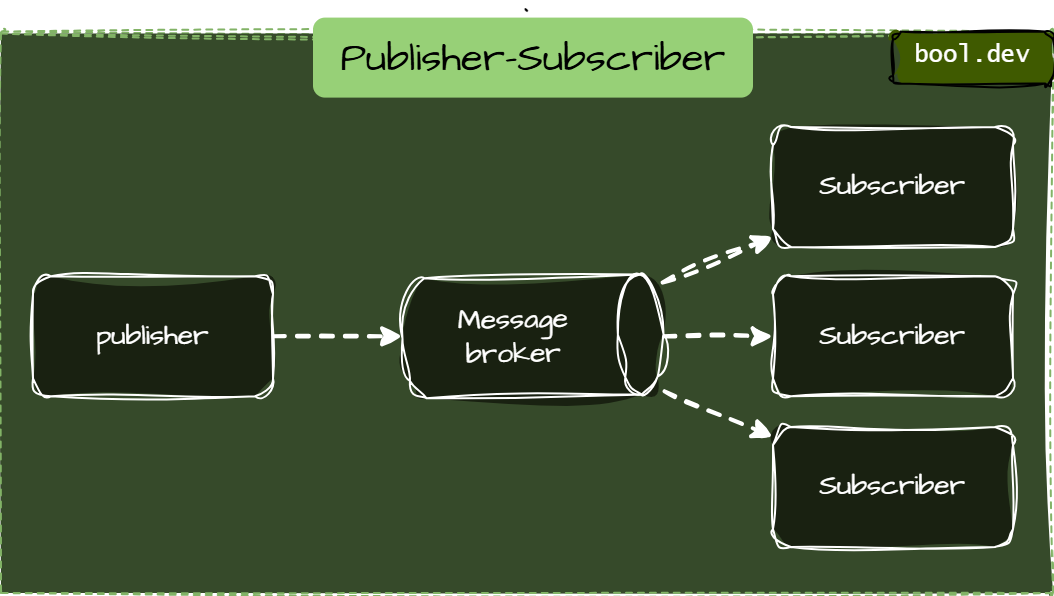
Publisher-Subscriber (Pub/Sub) pattern is used to share updates efficiently. When one system publishes a change, only those systems that subscribe to the topic get the update. For example, messaging apps use this pattern to notify users about new messages in real-time, ensuring that only relevant users receive the notifications.
When to Use Pub/Sub:
- When you need to distribute data to multiple interested parties.
- Ideal for real-time systems needing fast updates.
🧑🍳 Real World Kitchen Analogy for Pub/Sub
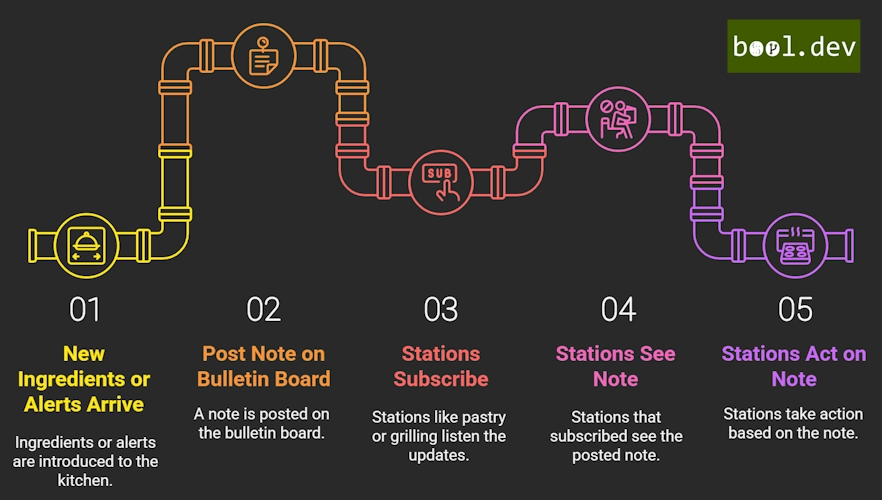
Only the stations that subscribed (e.g., pastry or grilling) see that note and act on it.
Request/Reply
In the Request/Reply pattern, data or service is provided only when requested. This is good for situations where you don't need constant data flow but want data on demand.
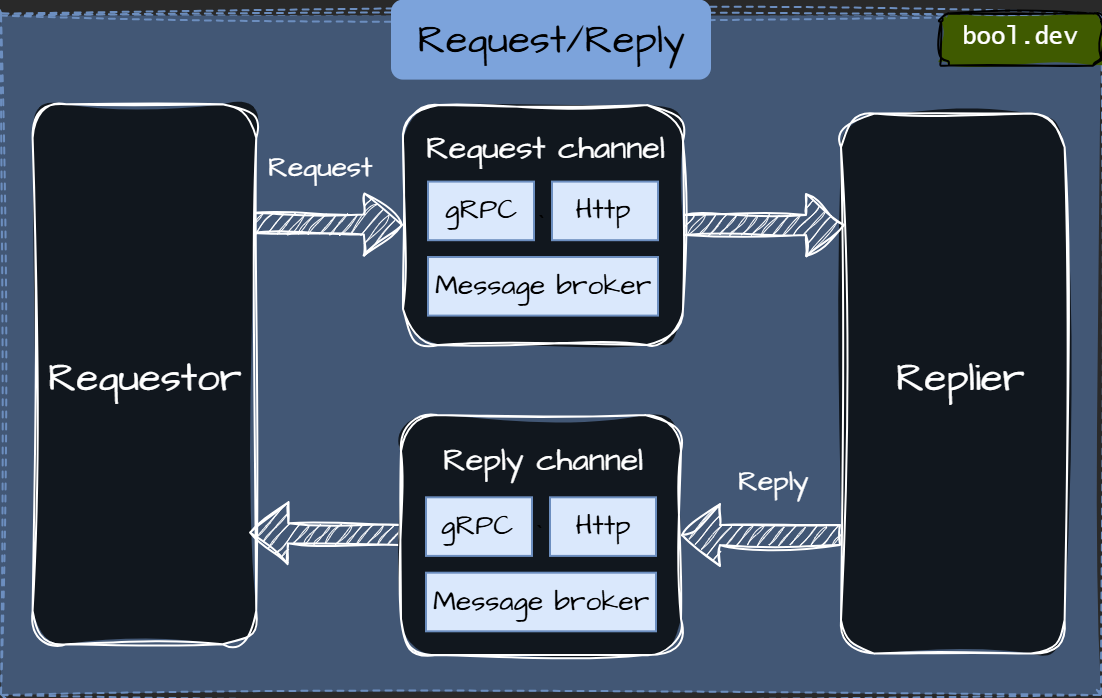
When to use request/reply
- When data is needed only occasionally.
- Good for systems that provide specific information on request.
🧑🍳 Real World Kitchen Analogy for request/reply

Point-to-Point Integration
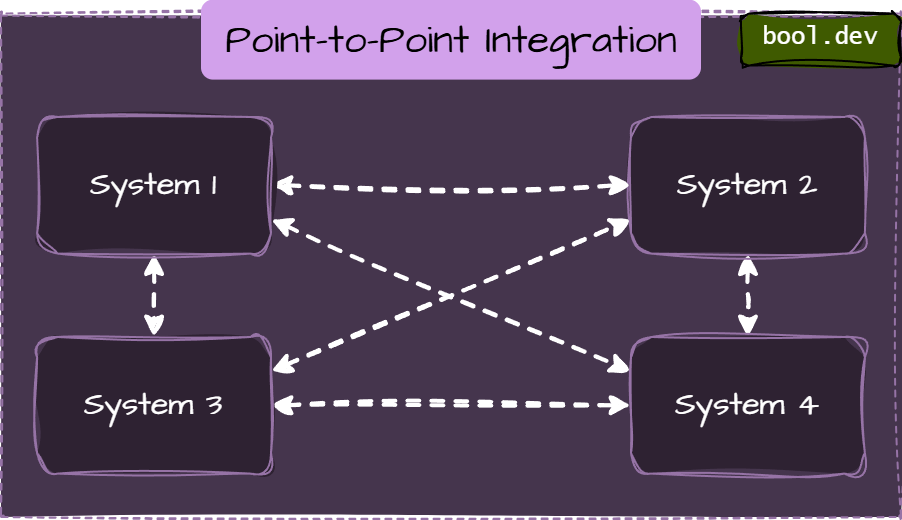
Point-to-point Integration is a tightly coupled integration between two or more endpoints, enabling communication to share data between the integrated parties. It is highly advantageous in scenarios where the universe of applications is small.
When to Use P2P
- For small projects or when only a few connections are needed.
- Ideal for simple data transfers without a middle layer.
🧑🍳 Real World Kitchen Analogy for Point-to-Point
It’s simple to set up for one or two connections.
But things can get tangled if you add more direct hoses for every new appliance.
Resources to read
- ETL vs ELT
- Change Data Capture (CDC)
- What is ETL (Extract Transform Load)?
- Extract, transform, and load (ETL)
- MongoDB Data Federation
- Publisher-Subscriber pattern
- What is Pub/Sub Messaging?
- Asynchronous Request-Reply pattern
- Request/Reply pattern
Summary
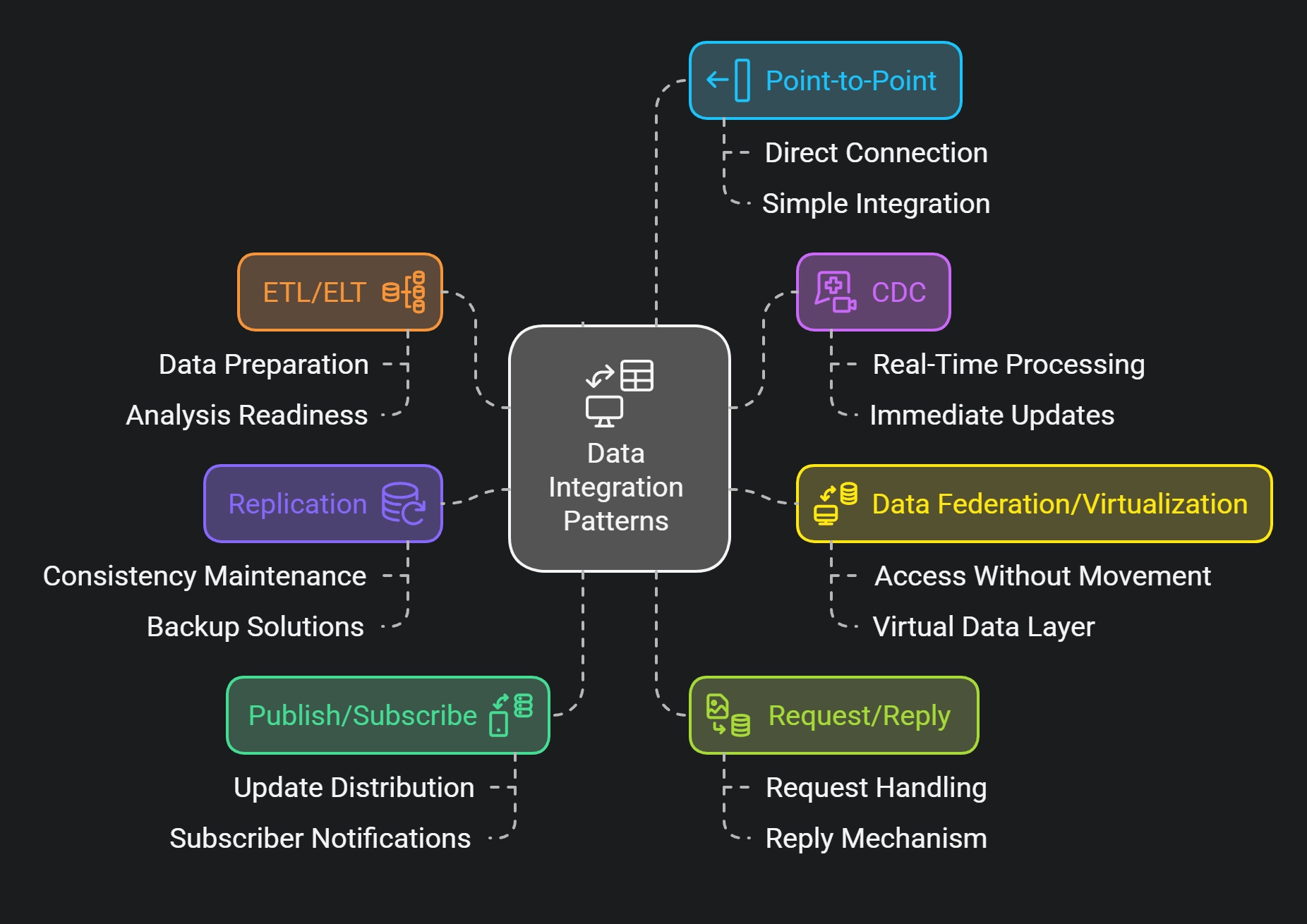
The best data integration pattern depends on what your project needs, like real-time processing, data consistency, scalability, and redundancy.
- Use ETL/ELT for preparing data for analysis.
- Use CDC for real-time updates.
- Use Data Federation or Data Virtualization for unified access to data without moving it.
- Use Replication to keep data consistent, or have backups.
- Use Publish/Subscribe to distribute updates efficiently.
- Use Request/Reply when data is needed on demand.
- Use Point-to-Point for simple, direct integrations.
Understanding and using these data integration patterns will help make your systems scalable, consistent, and more efficient, no matter how complex your organization becomes.
Data Integration Patterns Cheat Sheet